Artefacts にサインアップすると、いくつかのサンプルプロジェクトを含む artefacts-demos 組織に自動的に追加されます。
これらのプロジェクトの出力は https://app.artefacts.com/artefacts-demos でアクセスできます。
現在利用可能な例:
これは、このセクションの複数ページの印刷可能なビューです。 印刷するには、ここをクリックしてください.
Artefacts にサインアップすると、いくつかのサンプルプロジェクトを含む artefacts-demos 組織に自動的に追加されます。
これらのプロジェクトの出力は https://app.artefacts.com/artefacts-demos でアクセスできます。
現在利用可能な例:
デモはこちらからご覧いただけます。 注:登録が必要です
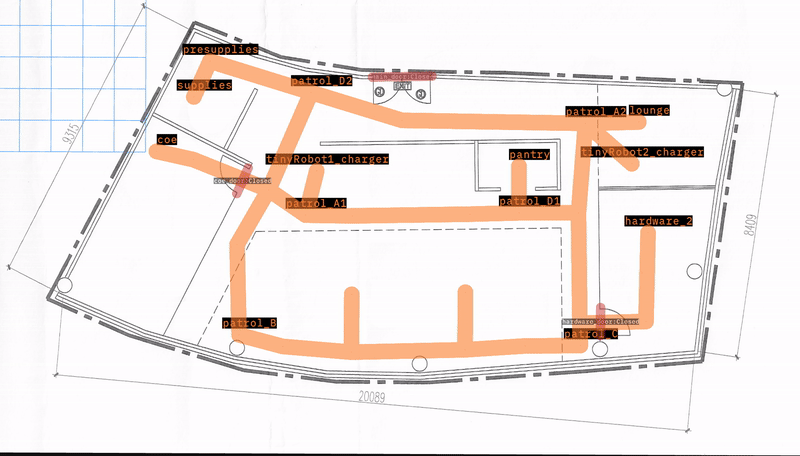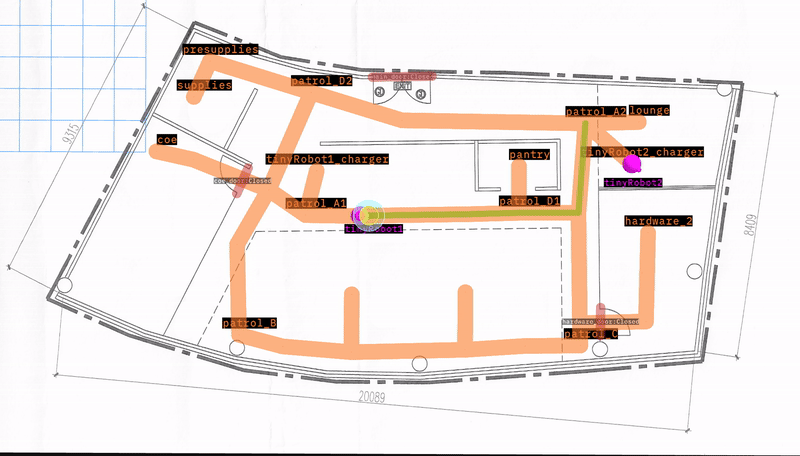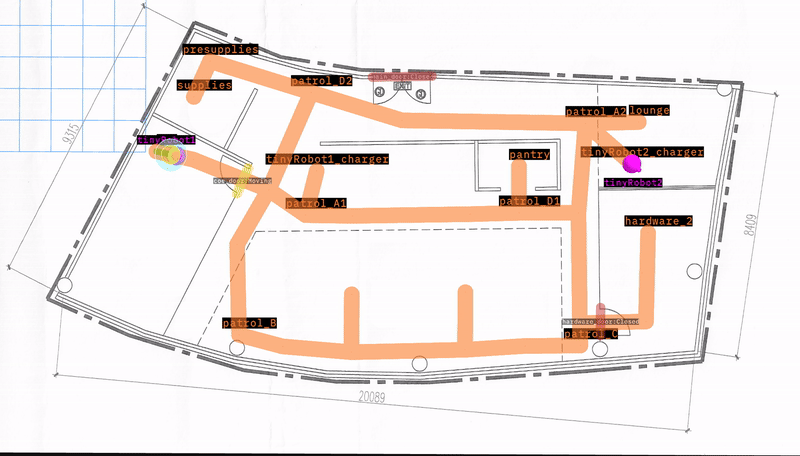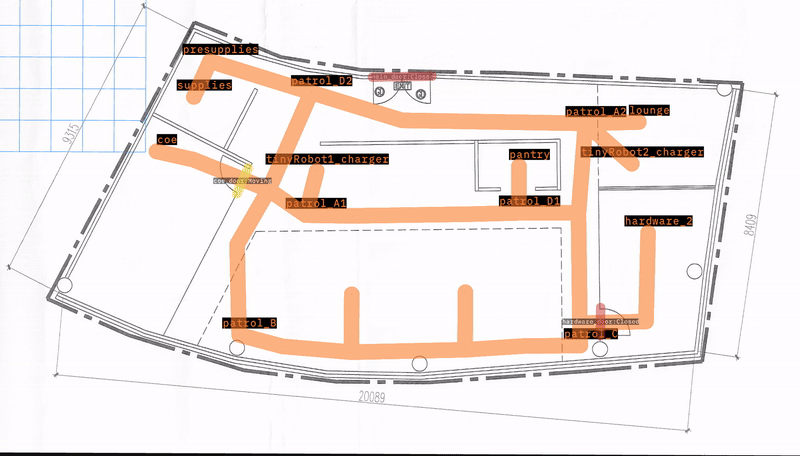
OpenRMFは、大規模建物における複数ロボットの相互運用性のためのフレームワークです。OpenRMFでの一般的な設定タスクの一つは、建物内のロボット用の場所とナビゲーションレーンを設定することです。
ここでは、office worldでOpenRMFデモを実行します。
以下に示すように、このマップにはロボットが移動できる14個のウェイポイントがあります。また、それぞれの充電器上で開始する2台の「tinyRobot」も含まれています。
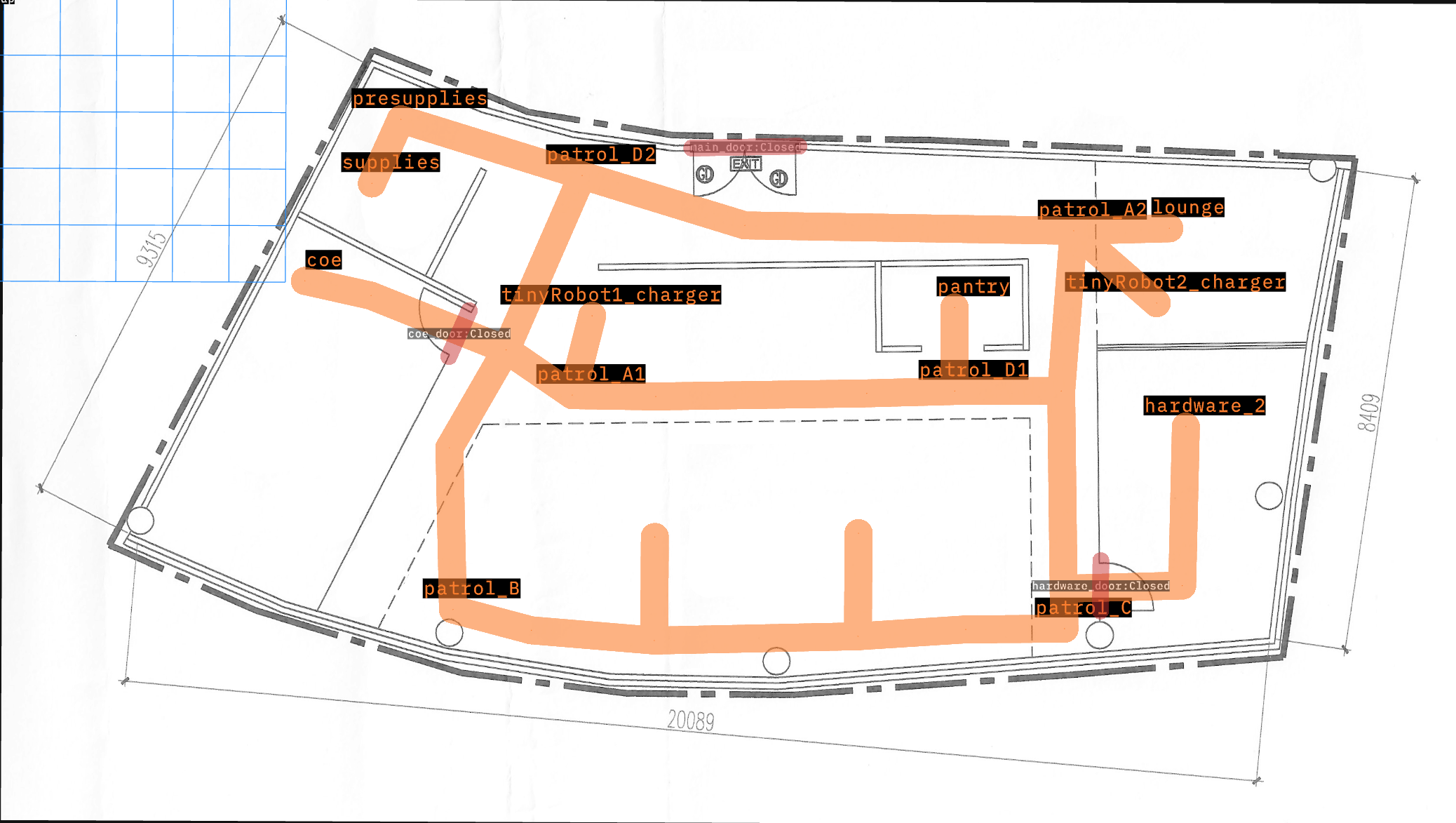
このテストデモの目的は、すべてのロボットをすべてのウェイポイントに送り、到着したことを確認することです。失敗は、ロボットがマップ上の場所に到達できないことを示します。
テストはすべてのロボットとウェイポイントを通じて実行されるようにパラメータ化されており、各実行の間にシミュレーションがリセットされます。
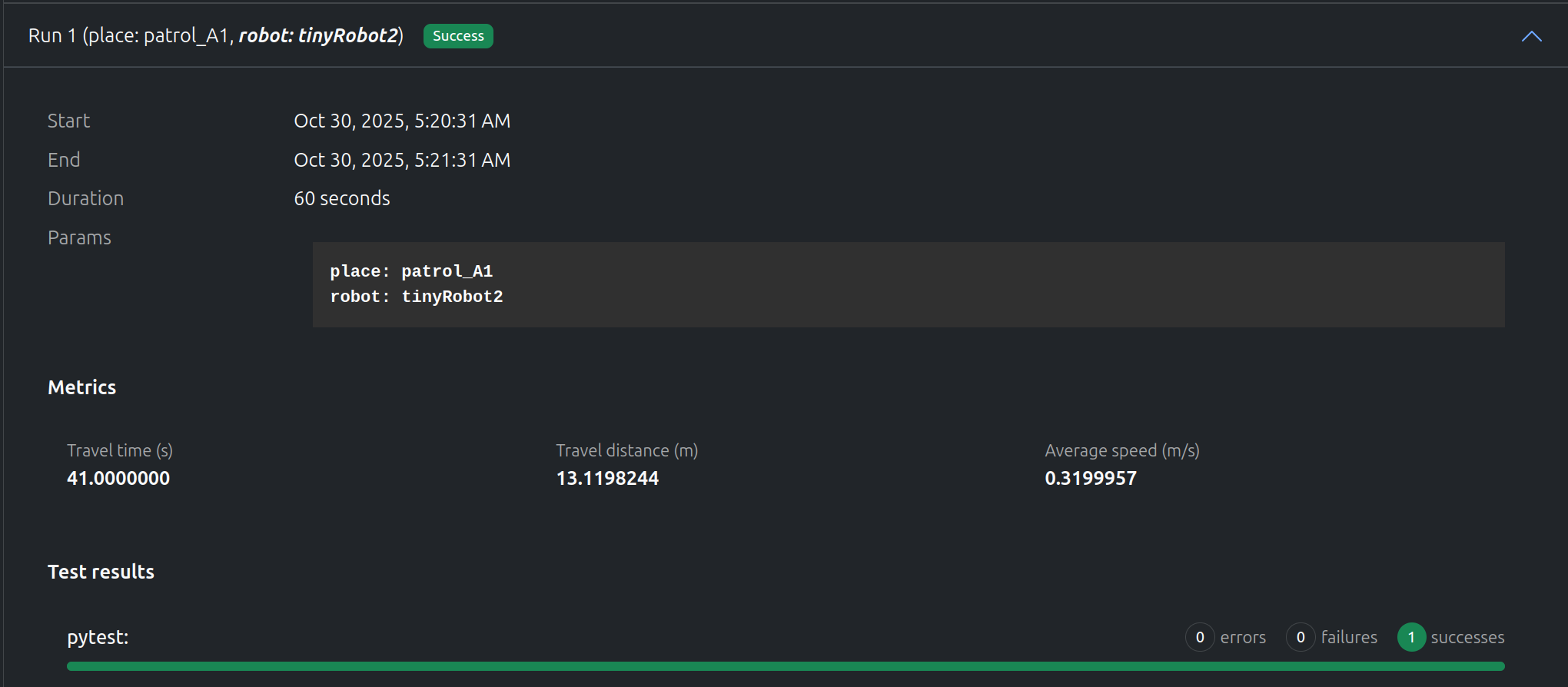
“tinyRobot2"は約40秒で"patrol_A1"に正常に到達しました。ビデオは、テストがどれだけうまく実行されたかについての追加情報を提供します。

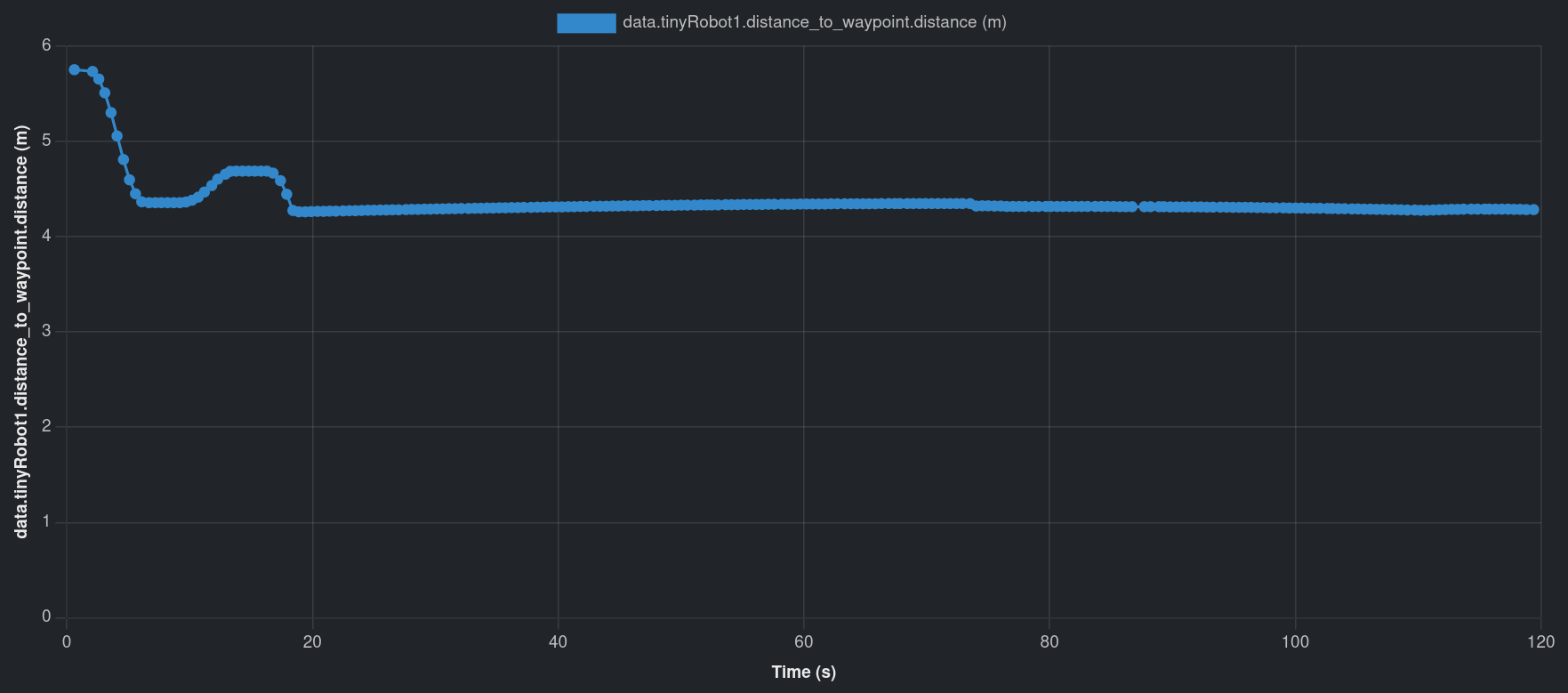
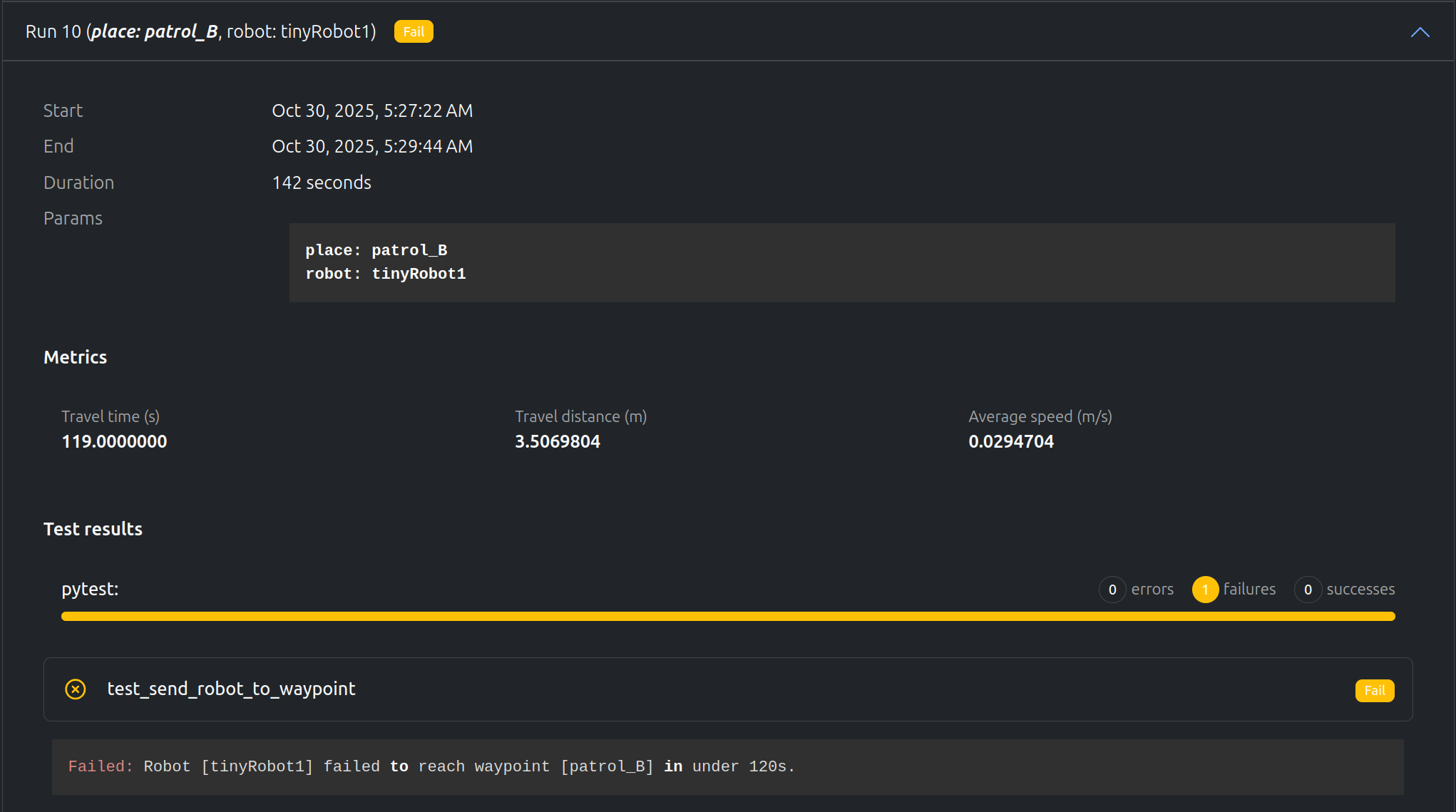
しかし、“tinyRobot1"は120秒のタイムアウト前に"patrol_B"に到達できませんでした。ビデオを使用すると、途中にゴミ箱があることに気づき、ロボットがそこで立ち往生しています。距離グラフもロボットがどこかで立ち往生していることを示しています。

テストでは、いくつかのメトリクスを記録します:
テストでは複数のデータを記録します:
デモはこちらで利用可能。注意: 登録が必要です。
Model Predictive Path Integral (MPPI) は最適な軌道を選択するためのサンプリングベースの予測コントローラーで、ロボティクスコミュニティで一般的に使用され、Nav2スタックによって十分にサポートされています。
Nav2のMPPIプラグインのコア機能はその目的関数(クリティック)のセットであり、ロボットプランナーに望ましい動作を達成するためにチューニングできます。
このデモでは、ロボット(Locobot)が後退移動を避けるべきターゲット動作を調査します。これは(ロボティクス実践者によって好まれ、)。また屋内環境での安全上の懸念によるもので、人間やペットがいる可能性があり、標準的なロボット(つまり: 前面センサーのみを持つ)が観測/認識なしに後退することは危険です。
この動作は、急旋回またはロボットに振り向くように求める再計画時(大きな角度距離)に、Nav2 MPPIのPath Angleクリティックが通常アクティブ化されスコアリングに貢献するために発生することが多いです。しかし、計画されたパスとの効率的な角度アライメントを達成するためにロボットを後退移動させる傾向があります。
最も直感的なソリューションはPrefer Forwardクリティックを使用し、そのウェイトをPath Angleクリティックよりも高いコスト貢献になるようチューニングして、後退動作に対抗することです。しかし、手動でこれをチューニングする場合(つまり: 盲目的にウェイトを調整する)、いくつかの疑問が残ります:
Artefactsを使用して、これらの答えをサポートします:
artefacts.yamlはテストをセットアップし、次のようにパラメトリゼーションします:
nav2_mppi_tuning:
type: test
runtime:
framework: ros2:humble
simulator: gazebo:harmonic
timeout: 10 # minutes
scenarios:
defaults:
output_dirs: ["output"]
metrics: "output/metrics.json"
params:
controller_server/FollowPath.PreferForwardCritic.cost_weight: [0.0, 5.0, 70.0]
settings:
- name: reach_goal
pytest_file: "src/locobot_gz_nav2_rtabmap/test/test_mppi.py"
キーポイント:
pytestを使用して実施され、pytest_fileは私たちのテストファイルを指しますoutput_dirsで定義されたフォルダ内のファイルを収集し、ダッシュボードにアップロードします。controller_server/FollowPath.PreferForwardCritic.cost_weight: ウェイト値をパラメトリゼーションします(クリティックコストデバッグプロットの観察後に取得)。ここでの構文はROSパラメータを示し、このフォーマットに従います: [NODE]/[PARAM]、そしてNav2パラメータ.yamlファイルで見つけることができます。テストは3つのウェイト値で3回実行されます: 0.0(貢献なし)、5.0(中程度の貢献)、70.0(高い貢献)。
Artefactsダッシュボードのラン比較はクリティックデバッグプロット(“Critics vs Time”)と結果軌道プロット(“odom vs gt positions”)を可視化します。ここでodomはロボットの推定オドメトリで無視でき、gtグラウンドトゥルースポジションに注意を払います。
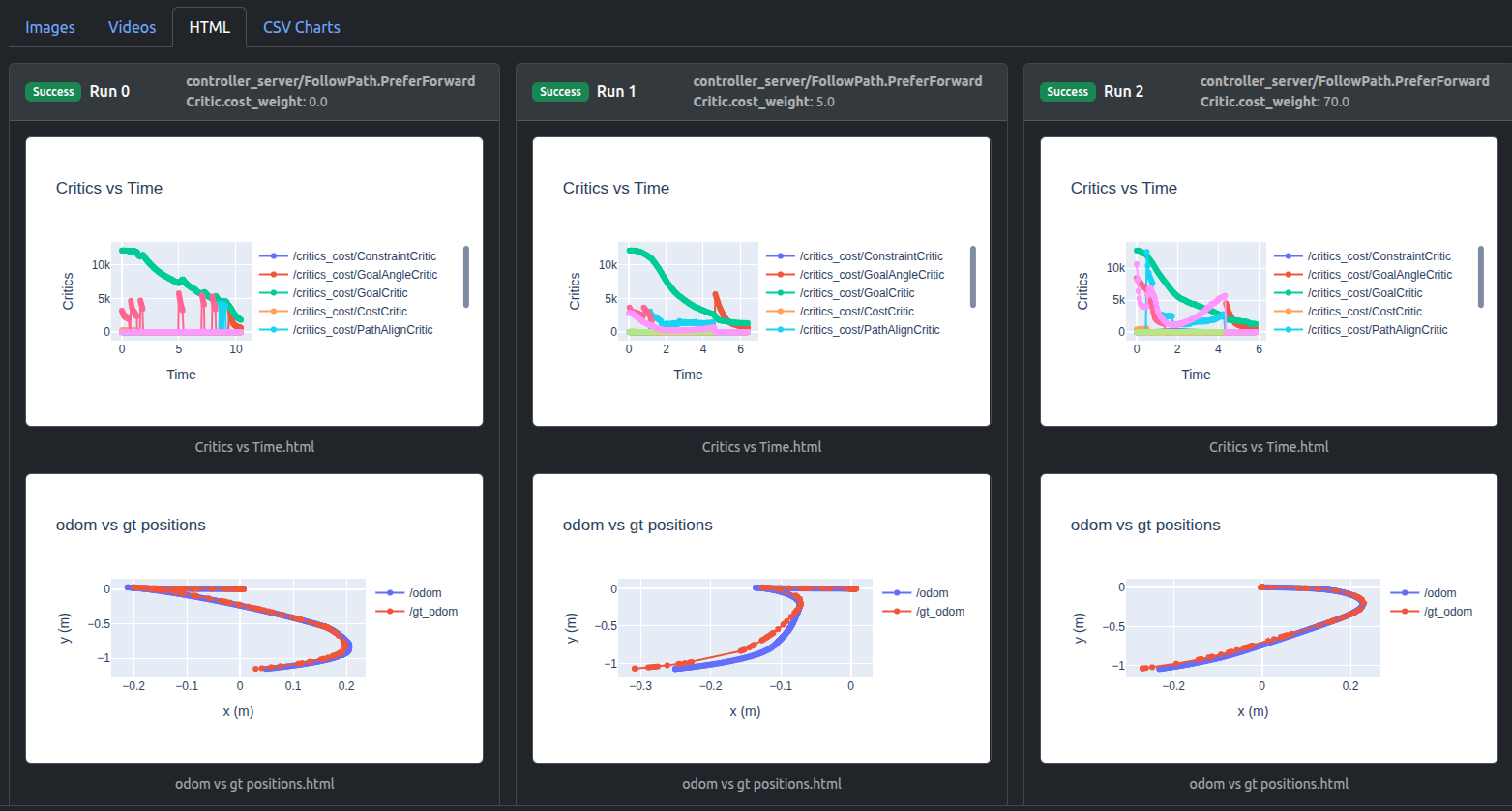
クリティックデバッグプロットでは、1つのクリティックをダブルクリックし、次に任意の次のクリティックをシングルクリックすることで、関心のあるクリティックを分離できます:
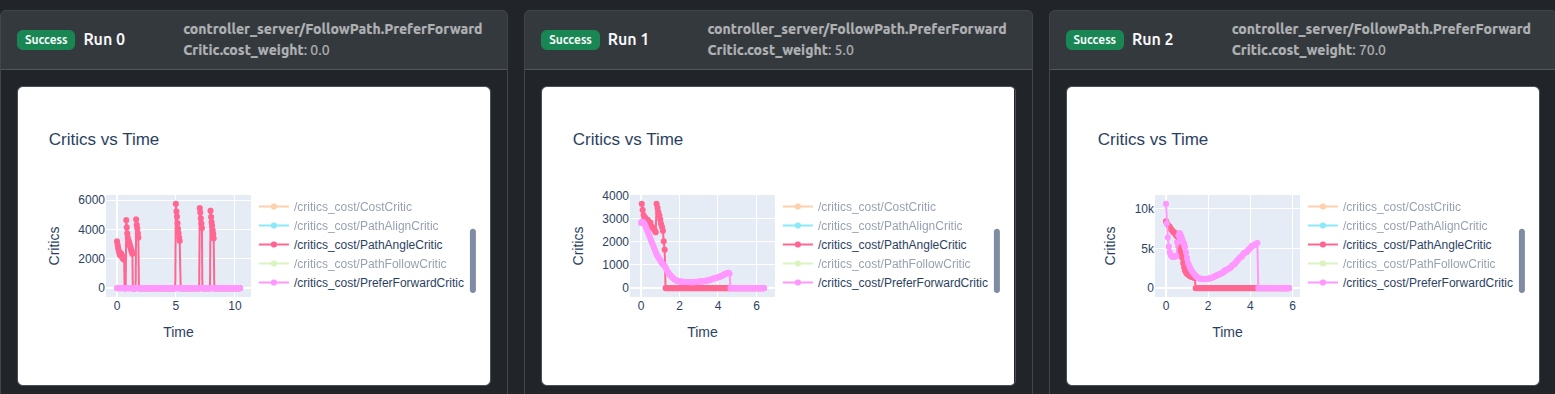
ウェイト0.0はゼロコスト貢献をもたらし、ウェイト5.0はPreferForwardCritic貢献をPathAngleCriticとほぼ同じに上げ、一方ウェイト70.0はその貢献を十分に上回ることができることがわかります。
軌道プロット(HTMLまたはCSVフォーマット)はPreferForwardCritic貢献の増加の影響を示します:
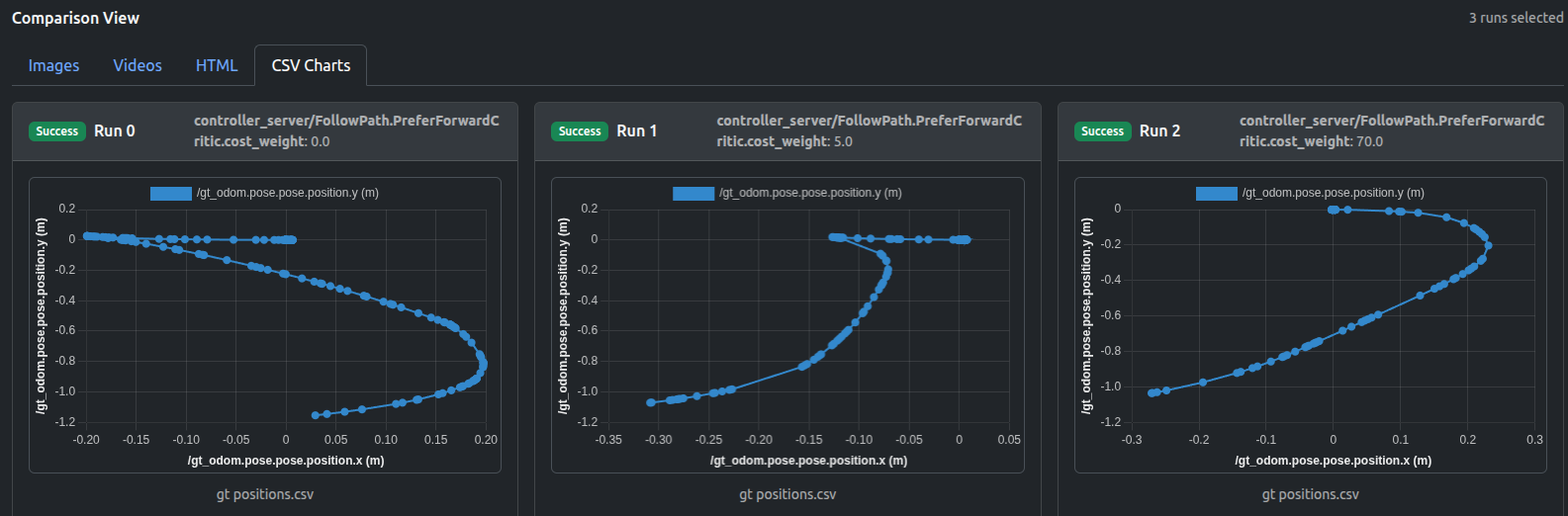
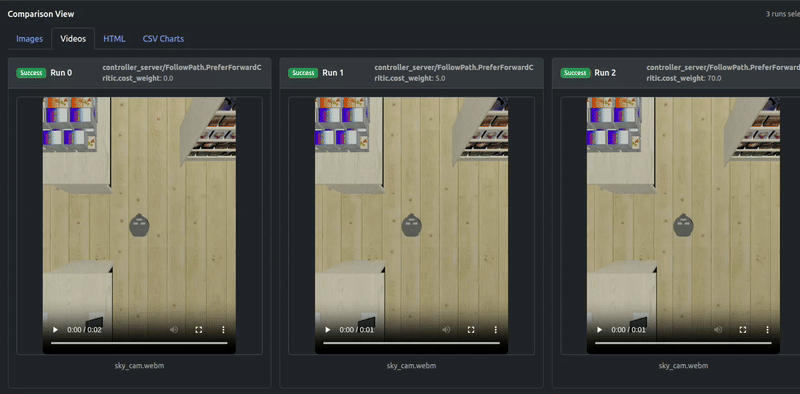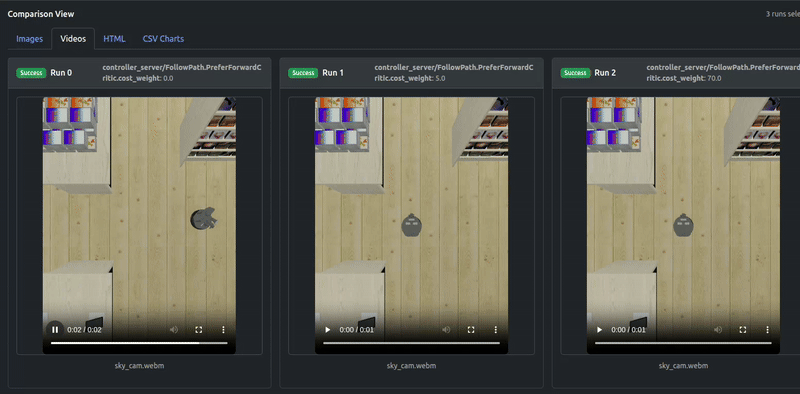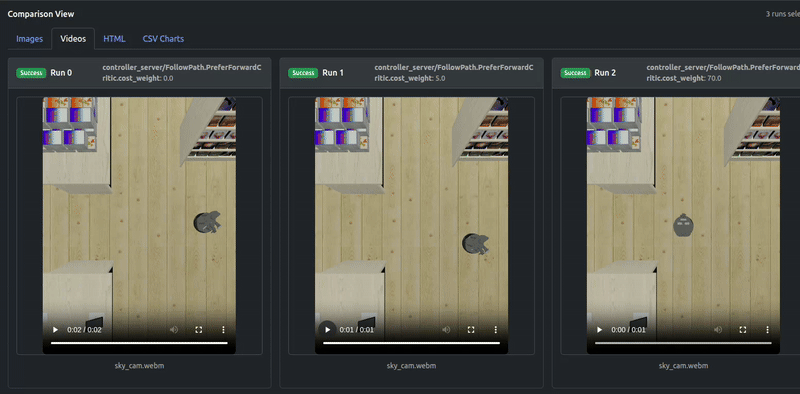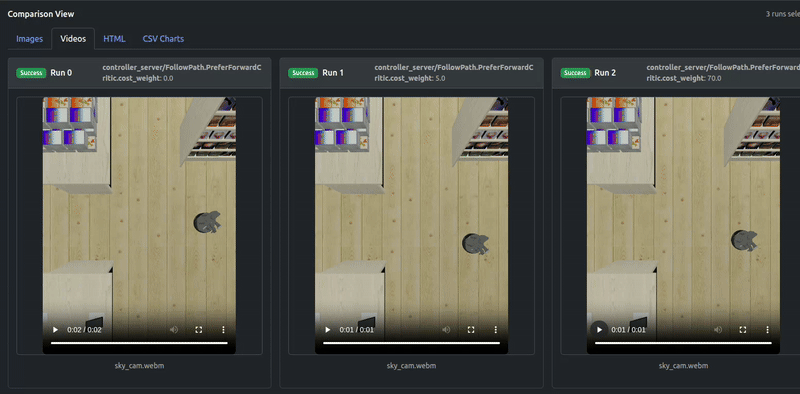
PreferForwardCriticの貢献がPathAngleCriticを上回るまで(ウェイト70.0)、ロボットのいくつかの「後退移動」動作が残り、一方ウェイト70.0はLocobotが前進のみすることを成功裏に保証できることがわかります。
出力ビデオも結果を確認します:
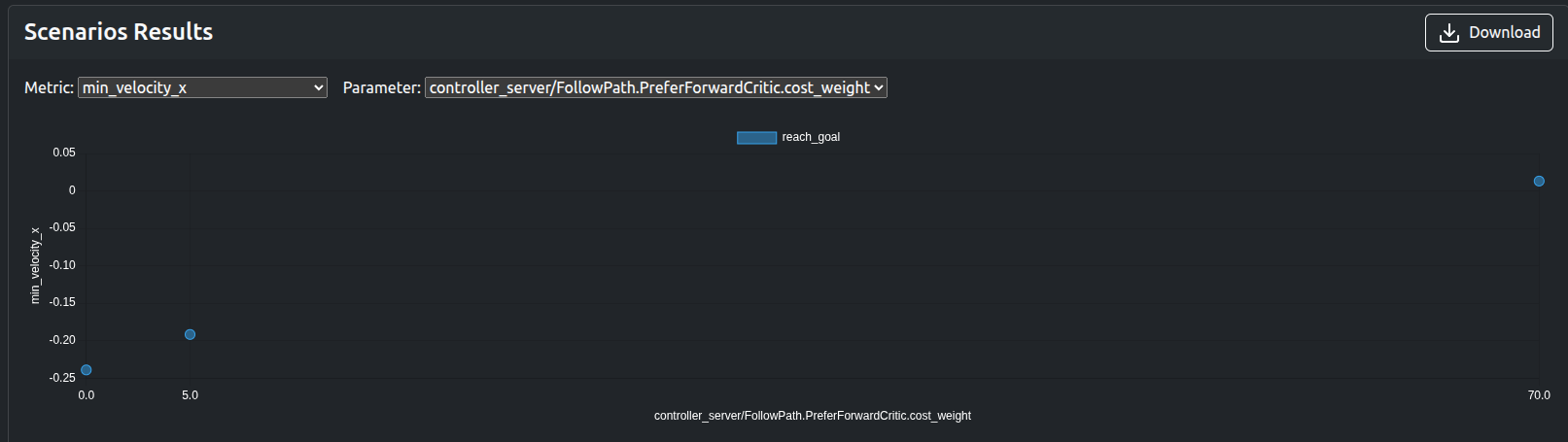
min_velocity_x、traverse_time、traverse_dist、PreferForwardCritic.costs_meanなどの数値メトリックは、可視化なしで結果を迅速に検証するために使用できます:
PreferForwardCritic(ソフト制約)はロボットの後退を避けるためのチューニングプロセスでこのデモでターゲットとされましたが、別のアプローチは単にvx_min = 0.0(ハード制約)を設定することで、これはコントローラーが負の前進速度をサンプリングすることを防ぎます(本質的に後退の厳格な禁止)。「ソフト制約」のウェイトを増やすと前進移動がはるかに可能性が高くなりますが、すべての前進サンプルが悪い場合(つまり: パスがブロックされている、狭い廊下でゴールがロボットの後ろにある)、MPPIは後退軌道を選択できますが、これは「ハード制約」の場合は不可能です。
しかし、一般的な慣行として最も単純なアプローチ(vx_min = 0.0の設定)から始める場合、または後退動作が望ましくない他の状況に対処しようとする場合(つまり: 後退移動でのステアリング問題、またはロボットが単に後退できず、狭い廊下にいる)、同様のパラメトリゼーションされたテストプロセスは、Artefacts .yamlコンフィギュレーションを拡張する(新しいジョブを追加する)ことで単純に実施できます。
jsonフォーマットのメトリックHTMLフォーマットのクリティックデバッグプロットHTML、CSVフォーマットの軌道このプロジェクトでは、Artefacts Toolkitから次のヘルパーを使用しました:
get_artefacts_params: どのPreferForwardCriticウェイト値を使用するかを決定するためextract_video: 記録されたrosbagからビデオを作成しましたデモはこちら。注:登録が必要です。
Tron1 ロボットは、ヒューマノイド RL 研究に使用できるマルチモーダル二足歩行ロボットです。ソフトウェアの多くはオープンソースで、こちら にあります。
このプロジェクトでは、2 つの強化学習ポリシーを 2 つの補完的な条件で評価します:
これらを組み合わせることで、ポリシーの 能動的な歩行性能 と 内在的な安定性特性 の両方を確認できます。
高レベルの目的(二足歩行)は同じですが、訓練環境と設計上の前提が異なる2つの強化学習ポリシーを比較します:
isaacgym
NVIDIA Isaac Gymを使用して訓練されたポリシーで、高速で大規模なシミュレーションと効率的な最適化を重視しています。これらのポリシーは通常、簡素化または厳密に制御された動力学の下で、コマンドされた動作の堅牢な実行を優先します。
isaaclab
Isaac Labを使用して訓練されたポリシーで、モジュール性、より豊かなタスク抽象化、下流のロボティクスワークフローとの密接な連携を重視しています。これにより、ポリシーに追加の内部構造と制約が導入されることがよくあります。
実装の詳細とトレーニングセットアップは以下で入手可能です:
まず、ロボットに開始姿勢から前進および回転するよう指示する動作テストを実行します。これにより、各ポリシーがシンプルだが重要な移動タスクをどの程度うまく実行するかを評価します。
テスト自体は以下の通りです:
artefacts.yaml で以下のように設定します:
policy_test:
type: test
runtime:
framework: ros2:jazzy
simulator: gazebo:harmonic
scenarios:
defaults:
pytest_file: test/art_test_move.py
output_dirs: ["test_report/latest/", "output"]
settings:
- name: move_face_with_different_policies
params:
rl_type: ["isaacgym", "isaaclab"]
move_face:
- {name: "dyaw_150+fw_5m", forward_m: 5.0, dyaw_deg: 150, hold: false, timeout_s: 35}
ポイント:
pytest で実行します(pytest_file でテストファイルを指定)。output_dirs の 2 つのフォルダを参照します。rl_type: "isaacgym"、"isaaclab"move_face: 前進 5m、回転 150 度、タイムアウト 35 秒テストは 2 回実行し、1 回目に isaacgym、2 回目に isaaclab を使用します。両方とも move_face の設定で移動距離と回転量を決めます。
isaacgym ポリシーでは、バードアイ動画で回転後に前進している様子が確認できます:

ダッシュボード上でも成功として記録されています:
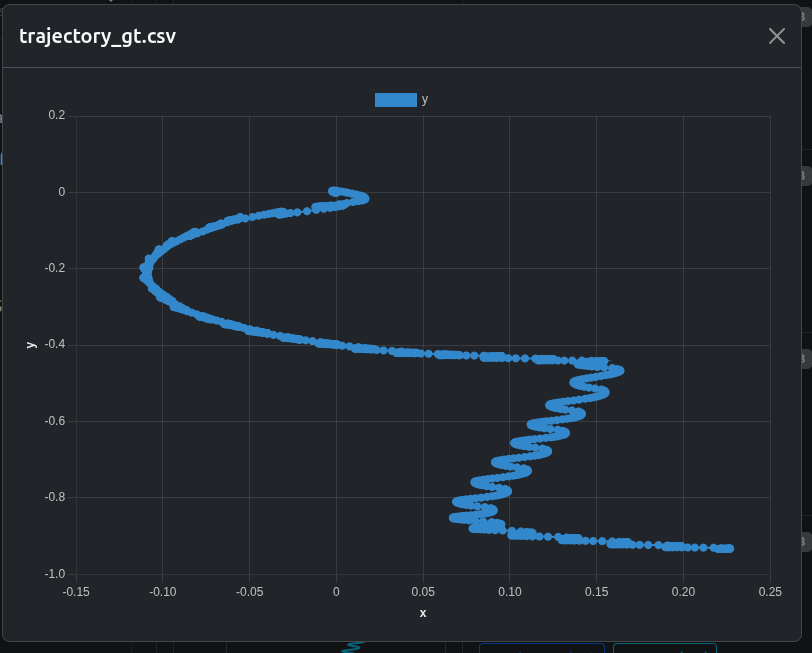
テスト中に作成したグラウンドトゥルース軌跡の csv も、自動でチャートに変換されています。
isaaclab ポリシーでは、まだ改善が必要です。ダッシュボードではテスト失敗(失敗したアサーションを表示)となり、バードアイ動画でも目標未達がわかります。

推定軌跡(ロボットが「自分はこう動いた」と考えている軌跡)の csv(自動チャート化)もあり、グラウンドトゥルースと大きく異なります:
移動テストはコマンド下でのタスク実行を評価します。これを補完するため、アイドルドリフトテスト(移動コマンドを一切与えないテスト)も実施します。
ロボットをニュートラルな直立姿勢に初期化した後、速度・姿勢・歩行コマンドはいっさい送りません。ポリシーは通常通り動き続けるため、観測される挙動はすべて非コマンドのものになります。
このテストはタスク実行とは独立した 受動安定性の挙動 を見ます。
アイドルドリフトは 2 つの時間スケールで評価します:
両方を見ることで 短期安定性 と 長期の平衡挙動 を切り分けられます。
policy_drift:
type: test
runtime:
framework: ros2:jazzy
simulator: gazebo:harmonic
scenarios:
defaults:
output_dirs: ["test_report/latest/", "output"]
metrics: "output/metrics.json"
pytest_file: test/art_test_drift.py
settings:
- name: idle_drift_compare_policies
params:
rl_type: ["isaacgym", "isaaclab"]
durations_s: [10, 60]
ポイント:
pytest で実行します。(policy, duration) の組み合わせに対応します。metrics.json に書き出され、ダッシュボードに自動表示されます。各時間スケールで、2 つのポリシーをバードアイ動画で並べて比較します。
| isaacgym | isaaclab |
|---|---|
 |
 |
| isaacgym | isaaclab |
|---|---|
 |
 |
各アイドルドリフト実行では、次のグラウンドトゥルースメトリクスを報告します:
ダッシュボードのメトリクスパネル例:

ビデオ観察を補完する、コンパクトで定量的なサマリです。
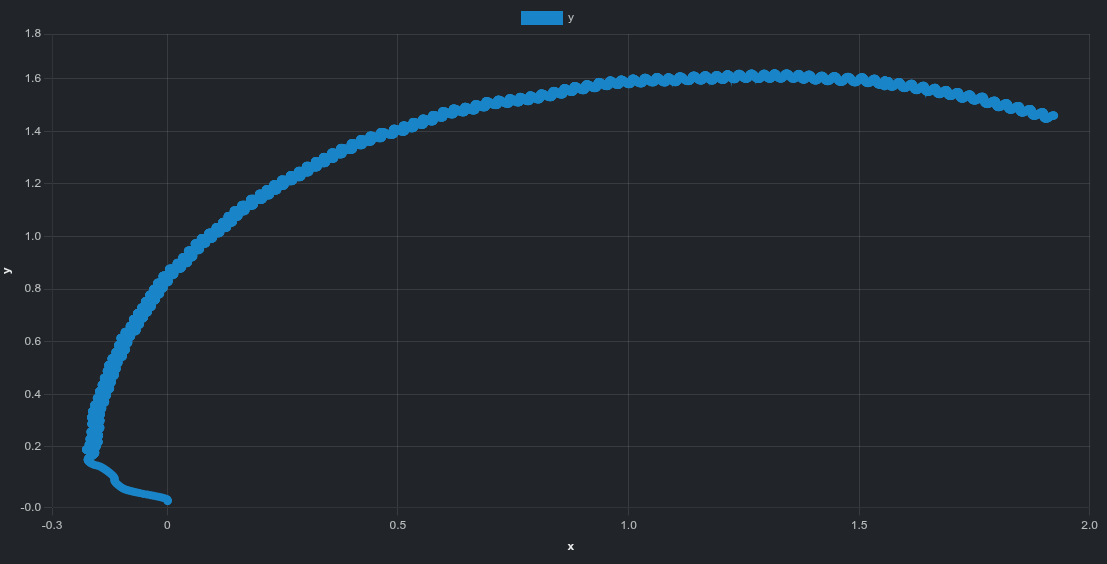
スカラー値に加えて、グラウンドトゥルース姿勢データから生成した平面軌跡のインタラクティブプロットもあります。
| isaacgym | isaaclab |
|---|---|
 |
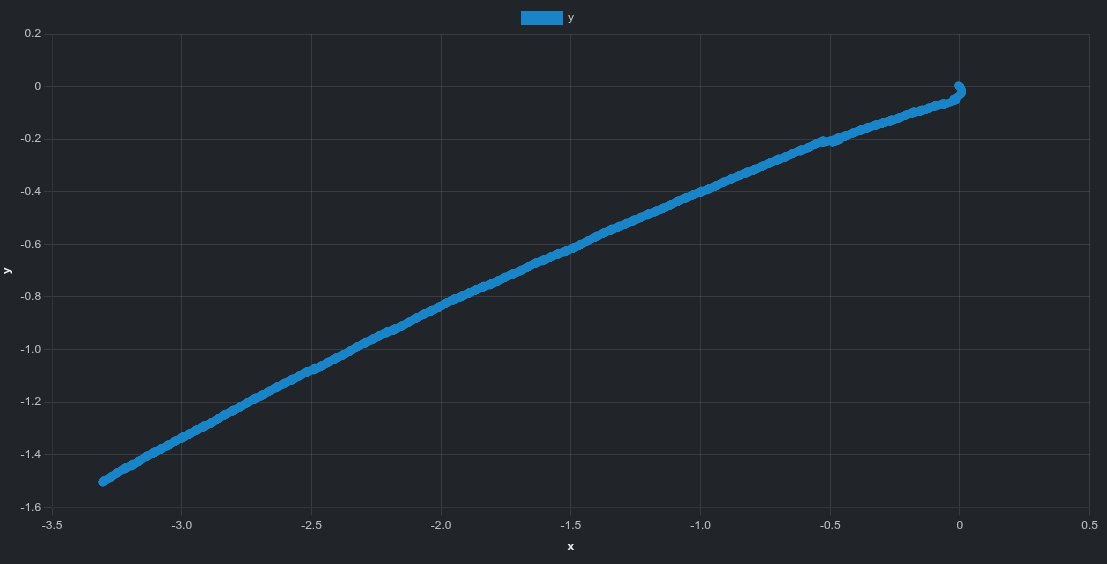 |
isaacgym は曲線的なドリフト軌跡を示します。isaaclab はより直線的なドリフト方向を示します。| isaacgym | isaaclab |
|---|---|
 |
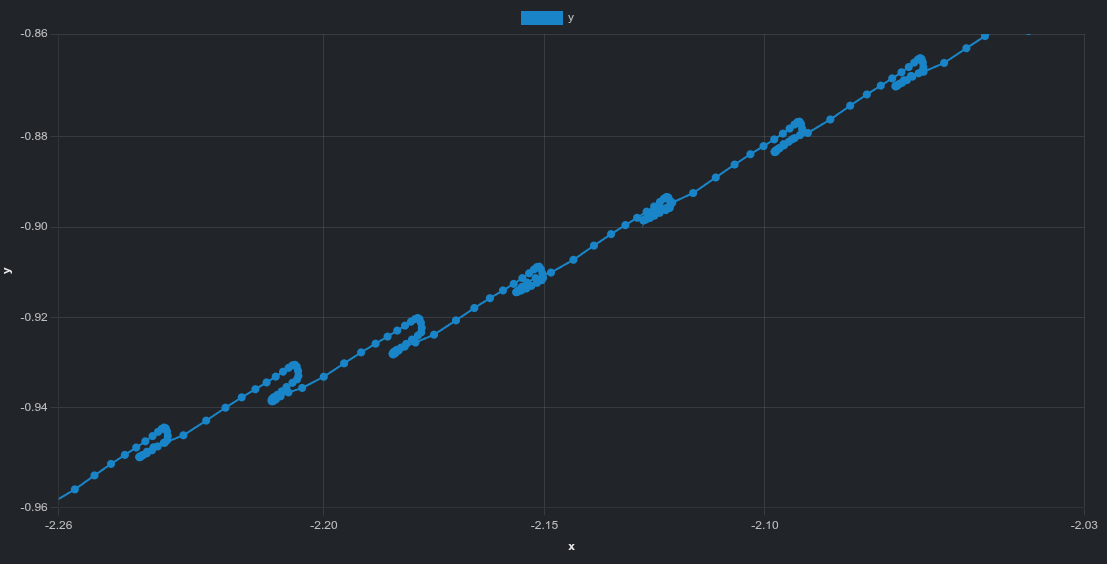 |
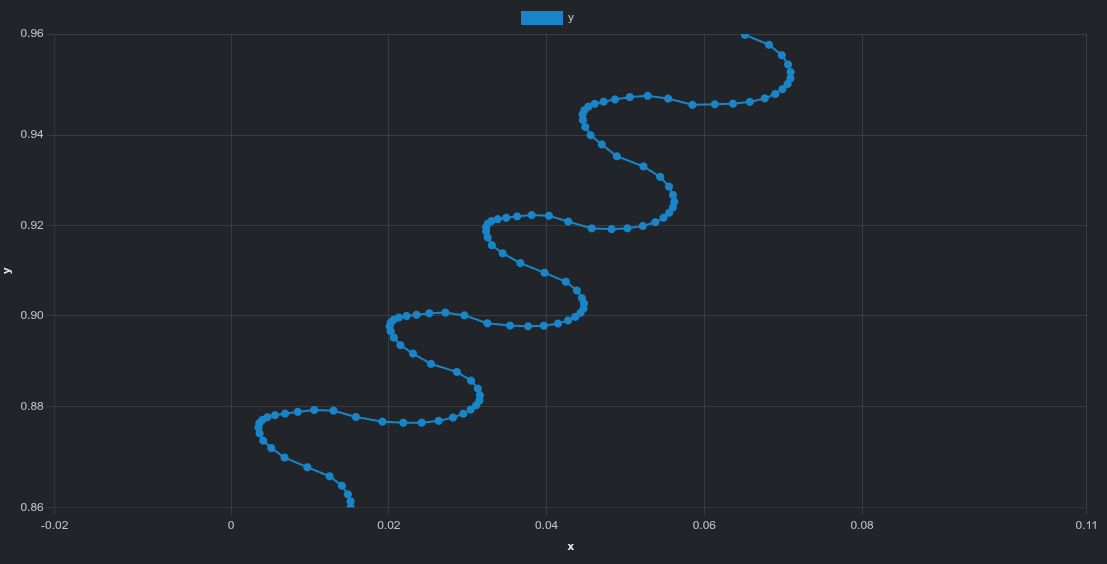
拡大すると次の細かな構造が見えます:
isaacgym は周期的な揺れisaaclab は小さいながら不規則なズレ動画では見えにくいパターンも、軌跡データで明確になります。
移動テストとアイドルドリフトテストは互いに補完的です:
両方を見ることで、能動状態 と 待機状態 の挙動を把握し、実行エラーと内在的安定性を切り分けられます。
移動テストとアイドルドリフトテストの結果として、Artefacts から次のデータにアクセスできます:
このプロジェクトでは、Artefacts Toolkit から以下を使用しました:
get_artefacts_params: 使用する RL ポリシーとテストパラメータの選択に利用extract_video: 記録した rosbag から動画を生成